Fake Words Are Based On Real Words
Each month, PanLex generates and publishes new “fake words” such as unequalitis and adjustache to entertain our newsletter readers in the Fake Word of the Month challenge. But how, exactly, are these fake words generated? We use an emergent property of the linguistic information contained in the PanLex Database, and a simple probabilistic algorithm.
Translation quality
If you have used the PanLex Translator, you may have noticed that beside each translated word is a small red bar, of varying lengths. This bar represents PanLex’s translation quality score, a measure of the level of confidence we have in that particular translation of the original word into the target language. The translation quality score is based on the number of PanLex sources the translation is found in, and the quality of those sources. (PanLex can also infer translations that are not directly attested in any single source. We will leave discussion of inferred translation quality scores to a future post.)
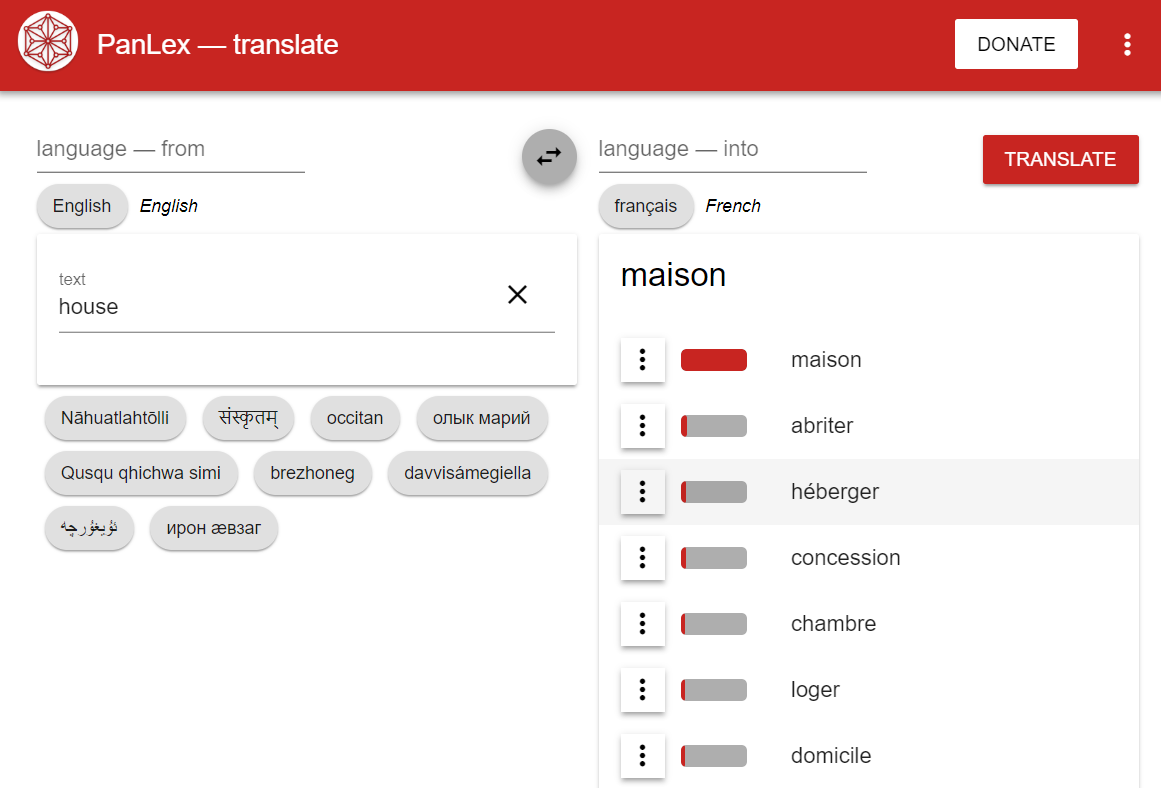
PanLex Translator App with red bars indicating relative quality of translations of English “house” into French.
Each of the thousands of sources (dictionaries, databases, etc.) that PanLex consults for translation data is assigned a quality score ranging from 0 to 9 indicating our opinion of the accuracy of translations based on the source. A well-researched dictionary by a trained linguist will receive a quality score of 8 or 9. A simple wordlist produced by a hobbyist and published on a blog may receive a much lower score. These quality scores allow PanLex to make use of a very wide variety of sources, especially for languages with scant published data, while maintaining accuracy in translation results. To calculate a translation’s quality, we sum the quality scores of all the sources that attest the translation. This means that a high score can result from a translation that is attested either in a few high-quality sources or many low-quality sources.
Unexpected benefit
An interesting unintended property discovered early in the history of PanLex is that not just translation quality scores can be calculated, but also expression scores. An expression score is sum of the quality scores of the sources in which the expression (an individual word or word-like entry) is found. An expression score is essentially a representation of how likely an individual word is to be found in a dictionary, and the PanLex team hypothesizes that it is an approximation of the likelihood that the word is part of a speaker’s vocabulary. For example, a word like house is likely to be found in many translation dictionaries and receives a very high expression score. It is also extremely likely to be in a speaker’s vocabulary. On the other hand, a more obscure word like stoat is found in a lot fewer dictionaries, receives a much lower expression score, and is also much less likely to be part of a speaker’s vocabulary.

White stoat. (Image by Rodman Nail.)
We believe that emergent properties in the PanLex Database such as expression scores are an area ripe for further research, both inside and outside the PanLex team. One such project, albeit very silly, was developed by two PanLex collaborators: myself (Ben Yang) and Alex DelPriore, a former PanLex source analyst. By feeding all of the PanLex expressions in a given language into a character-based Markov Chain text generator, and weighting each step by PanLex expression scores, the output would be words that were not present in a given language, yet exhibit letter patterns characteristic of that that language and thus sound like they should be valid words in that language.
A Markov Chain is essentially a very simple machine learning algorithm discovered in 1906 by Andrey Markov. It is produced by taking a series of linear events, and calculating the probability of each event that follows. For example, let’s say we took the entirety of the works of Shakespeare, and determined that whenever he wrote “good”, it was followed by “day” 20% of the time, “morrow” 30%, and “sir” 50%, and every time he wrote “day” it was followed by “to” 30% of the time, “sir” 60% of the time, and “my” 10% of the time. By chaining many of these decision trees together, one could create a giant decision tree aggregating all of them together, and by “walking” that tree by randomly choosing an option at each step weighted by how often that option was taken by Shakespeare, one could generate something that looked like Shakespeare wrote it, but was never written by the man himself.
At PanLex, we created Markov Chain model generators that took as their input all of the expressions in a given language, stepping through character by character rather than word by word as in the example above. We then tweaked the probability of each step by the expression score, making it as if expressions with higher expression scores had occurred multiple times in the input. Finally, any generated words that were already present in the PanLex Database were discarded. This turned out to work extremely effectively for many languages in PanLex. All of the fake words that have been featured in the PanLex Newsletter have been generated using this technique with the English data in the PanLex Database as its input. We intend to feature fake words in other languages as well, generated in the same way. Eventually we may make the generator available for general use as well.
Towards more authentic fake words
We’re also interested in improving the Fake Word Generator. It currently does not work effectively on anything written with Han characters such as Chinese or Japanese, as it generates new words character by character, which is effective for writing systems where words consist of many characters, but not ones where the vast majority of words consist of one or two characters at most. One solution we’re exploring is essentially “blowing up” each Han character into its constituent parts, generating a novel sequence of character parts, and then recombining the shuffled character parts into new characters.
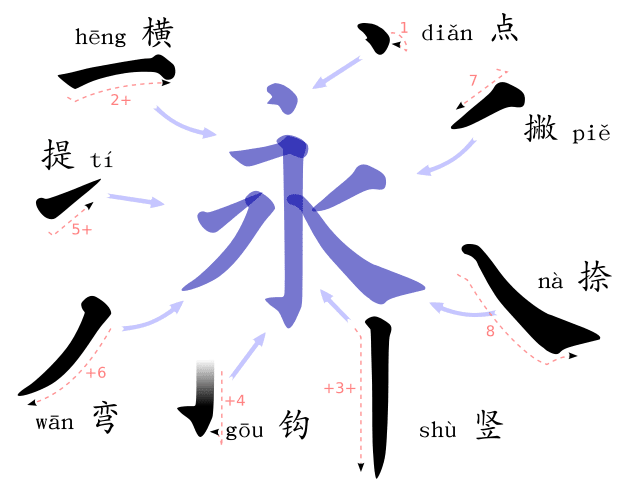
Strokes used in Chinese characters. (Image by user Yug. Source: Wikipedia.)
{kind=link}
Another avenue for improvement is in the application of more modern and complex machine learning techniques such as recurrent neural networks, which will allow the generator to create more convincing fake words in languages with long-distance dependencies, such as prefixes that always pair with certain suffixes, or grammatical patterns that only occur on certain classes of words.
While the PanLex Fake Word Generator may have initially seemed frivolous, and the output entertaining, it has resulted in some important discoveries about the properties of the PanLex Database and the potential use of expression scores in future research. We are excited about all projects that demonstrate the power and potential of our database. We look forward to our collaborations with you and other like-minded teams to discover new and provocative uses of it.
Leave a Reply