Enabling Radically Inclusive Machine Translation (part 1)
Could you ask your doctor about your sprained ankle in French or Indonesian? Would you understand your bus schedule in Mandarin or Arabic? Could you take your biology exam in Hindi or Vietnamese?

Bus schedule in Udon Thani, Thailand. (Image from Thai Blogs)
The Universal Declaration of Human Rights states that everyone has the right to access health care, education, legal services, and technology. Nearly 3 billion people in the world today cannot do so in their native language. Most of them feel pressure to learn the dominant language of their region in order to exercise their human rights and have access to opportunity. As a result of this pressure, more than a third of the world’s 7,000 languages are under-served or endangered.
The world is at a crossroads. We can choose a future where everyone must learn the dominant language to survive, perhaps ending at the point where only a few languages are still spoken on earth; or we can choose a future where everyone has the ability to preserve their language and culture as they see fit, while still being able to fully exercise their human rights and access opportunities. There is public debate over which future is more likely.
At PanLex, we believe that nobody should have their rights restricted because of the language they speak. No one should be forced to choose between language, identity, and culture (on the one side) and human rights and opportunities (on the other). PanLex is developing technological solutions that help create a future where this choice is no longer necessary.
The current situation
We believe that machine translation can help speakers of under-served languages use their native language to exercise their human rights and access information and services. Technology is only one factor in the continued vitality of a language, but it is an ever-increasing one in our globally interconnected world.
Machine translation, which Google Translate and similar services provide, is currently available in only about 100 of the world’s 7,000 languages. There are two major reasons that it is not yet available in most languages: economic and technical.
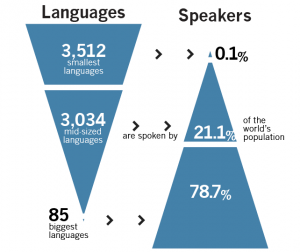
Illustration of the uneven numbers of speakers of languages in the world. Nearly 80% of the world’s population speaks only 85 (1.1%) of the world’s languages. The 3,586 (51.2%) smallest languages are spoken by only 0.2% of the world’s population. (Image courtesy of K. David Harrison, When Languages Die)
The most widely used machine translation services are developed by for-profit companies such as Google and Microsoft. These companies mainly target the largest and most important languages in their markets. This tends to increase the dominance of already-dominant languages and exclude smaller languages. We are hopeful that companies will increasingly see the value of reaching more customers in their native language, but economic incentives will always leave a gap. PanLex and other nonprofits, which exist to serve humanity rather than to seek profit, can help bridge this gap.
There are also significant technical challenges in bringing machine translation to all of the world’s languages. The most widely-used machine translation technologies today are statistical machine translation and neural machine translation. In order to develop a translation model between two languages, these technologies require massive amounts of parallel text—that is, translated documents available in both languages, such as websites, books, contracts, and manuals. The parallel text corpus must contain tens of millions of words for these technologies to work well. For most languages, the required parallel text corpus simply does not exist.
The way forward
PanLex was one of the first organizations to recognize the importance of making machine translation technology available in under-served languages. Over the past 12 years, PanLex has built the world’s largest lexical translation database. It is designed to translate any word from any language into any other language. It currently supports 5,691 languages, and many of those in multiple scripts and dialects. You can try it here.
There are many languages for which few or no parallel texts exist, but for which good translation dictionaries are available. We created the PanLex database to take advantage of this trove of vital translation data, making it accessible, long-lasting, and interoperable among all languages. Let’s unpack that a bit. Accessible: it is publicly available to all. Long-lasting: we are preserving language data for present use and future generations in digital format. Interoperable among all languages: translation data from each language is put into a consistent and standard format, thereby enabling direct translations and inferred translations in new language pairs—from any language to any language. This last is one of the most powerful features of our database.
We believe that the PanLex database is a critical component in developing viable machine translation in under-served languages. Rule-based machine translation is a technology that is particularly suitable when little parallel text is available. There are also hybrid approaches that combine the advantages of rule-based and statistical/neural approaches. These techniques all require an extensive word-translation dictionary to work well. This is what PanLex has created.
In future posts in this series, we will discuss our initiatives to improve translation support in under-served languages, describe PanLex’s unique role, and explore in more detail our vision to overcome the economic and technical challenges to machine translation in these languages.
Leave a Reply