Enabling Radically Inclusive Machine Translation (part 2)
In the first post in this series, we discussed the importance of bringing machine translation to all of the world’s languages and some of the economic and technical challenges in doing so. In this post, we will explore in more detail the current status of technological support for machine translation in under-served languages. Along the way, we will show that PanLex can make an important contribution to several current endeavors.
Existing machine translation platforms and initiatives
Google Translate is probably the most well-known machine translation platform in the world. It currently includes support for 103 languages, including some that are not national languages of any country such as Basque, Cebuano, Hmong, and Kurmanji Kurdish. Translation quality varies widely across languages. It is “good enough” for some purposes in some languages, and it improves regularly. But it has a long way to go, especially in language coverage.
The Apertium project is a free, open-source machine translation platform. Unlike Google Translate, which uses statistical and neural methods, it uses rule-based translation. One advantage of rule-based methods is that once an implementation has been created for one language, it is much less work to adapt it to a closely related language. This has allowed Apertium to develop support for several under-served languages that Google Translate has not, for example Breton (related to Welsh), Northern Sami (related to Finnish), and Tatar (related to Kazakh and Turkish).
Another advantage of rule-based methods is that they do not require a massive parallel text corpus (that is, translated documents available in both languages). For many languages, an adequate corpus does not exist and would be expensive and time-consuming to produce. Rule-based machine translation is not currently in vogue — it has significant disadvantages over statistical and neural methods — but it is a practical and cost-effective way of bringing machine translation to under-served languages. With sufficient funding — a few million dollars, which our civilization can surely spare — it would be possible to procure lexical data and expert-developed models for dozens of languages. This would greatly improve the level of translation support in these languages. The PanLex database provides the dictionary data that this method requires in a growing number of under-served languages.

An early example of a parallel text: William Caxton’s 15th century Dialogues in French and English. (Image from kʼaləbøl)
Large amounts of textual data are still needed in order to produce the highest quality machine translation. Gathering and creating this data is an important long-term project. This is just what Gamayun Language Equality Initiative, led by Translators Without Borders and involving a large number of industry partners, is doing. For 2018, their focus is on Bengali, Hausa, and Swahili. These languages are comparatively large — Bengali has 260 million speakers — but they are poorly supported. This makes them a great place to start, since the resulting data will help more people sooner.
The latest research
There must also be technological advancement to make machine translation possible in under-served languages. There are several recent, exciting developments in this fast-moving space.
MATERIAL (Machine Translation for English Retrieval of Information in Any Language) is a project funded by IARPA, an organization within the US Office of the Director of National Intelligence. Because it is aimed at intelligence use, its focus is on information retrieval rather than translation in general. It is nonetheless one of the largest research projects to tackle the problem of making statistical and neural machine translation methods useful when only a small amount of parallel text is available. A recent paper by MATERIAL-funded researchers Shearing et al. (2018) described using PanLex data to improve translation quality in low-resource languages.
Research in neural machine translation has recently explored multi-lingual neural translation, which involves building a single model going from multiple source languages into one target language. That is, the model can take text in any of several languages (for example, Spanish, French, and Italian) and translate it into a single target language (for example, Russian). A benefit of this method is that when the source languages contain a combination of high-resource (extensive parallel text available) and low-resource languages, the high-resource languages can significantly improve the quality of translation from the low-resource languages.
In a recent paper, Gu et al. (2018) describe a new method called universal neural machine translation, which they present as an advance over multi-lingual neural machine translation. Unlike multi-lingual translation, which essentially combines source languages into one big “language” for modeling purposes, universal translation maps each source language to a universal representation, which may then be translated to a target language. The universal representation they use is English, but other representations are possible.
The mapping from source language to universal representation is learned from a combination of monolingual text, a small amount of parallel text, and a dictionary from source language words to the universal representation. Source languages are coordinated with each other in the learning process, which means that the resulting model captures commonalities of meaning and usage among words and sentences in different source languages. The authors show that, compared to multi-lingual translation, universal translation produces higher-quality results, and with less parallel text. It is a great advantage of this method that it can make good use of dictionaries, as they often contain the most extensive available data on under-served languages — precisely why we have built the PanLex database around multilingual dictionaries.
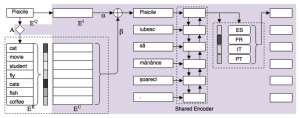
An illustration of Gu et al.’s model. (From their paper, Figure 2)
Conclusion
There is some current support for machine translation in under-served languages, and some exciting recent research and initiatives, but we are still far from the end goal. We have shown that PanLex has a central role to play: we can supply the broad lexical data that any method realistically must use in order to produce high quality results. In the next post in this series, we will describe in more detail what we do at PanLex, how our database differs from other resources, and why it is so important for enabling radically inclusive machine translation.
Leave a Reply