On November 25, the PanLex team began a month-long stay in Yogyakarta, a city on the island of Java in Indonesia. Mataram, the historical region in which Yogyakarta is located, was controlled by several medieval and early modern kingdoms, and then for two centuries was part of the Dutch East Indies. The region is home to two famous ancient temples, Borobudur and Prambanan.
The PanLex team is in Indonesia in order to investigate ways to support local under-served languages.We chose Indonesia for several reasons. First, it has many under-served languages with large numbers of speakers, such as Javanese (84M speakers), Sundanese (34M), Batak languages (7M), Buginese (5M), and Acehnese (3.5M). Second, our team already has extensive experience in Indonesia, and two of us speak Indonesian. Finally, it is a fascinating and beautiful place to spend a month!Read More…
In the first two posts in this series, we elaborated our belief that all people should be able to use their native language to exercise human rights and have access to opportunity. We showed that machine translation technology currently falls far short of this goal, but that there are realistic ways to make progress. In this third and final installment, we will describe in more detail our work at PanLex and how we are uniquely positioned to improve translation support in under-served languages.
We consider under-served languages to be those lacking institutional support from governments or support from major technologies such as Google Translate, Android, or Microsoft Windows. Of the world’s 7,500 languages, 6,900-7,400 are under-served. More than 2 billion people speak under-served languages, including large languages such as Western Punjabi (90M speakers), Javanese (84M), Wu Chinese (80M), Egyptian Arabic (62M), and Uyghur (10M).

Uyghur boys. (Image by OMF)
Read More…
The relationship between food and language can be fascinating. The idiosyncrasies of a culture’s cuisine are often reflected in its vocabulary, and it is common for food words in one language to lack direct translations into other languages due to the uniqueness of cuisines around the world. Of course, a culture can adopt other foods, ingredients, and techniques, but when it does, the names are often borrowed along with the concepts themselves. Sushi, for example, is a wanderword, with examples such as Cherokee ᏑᏏ (susi), Azerbaijani suşi, and Bengali সুশি (suśi). (Wanderword is a term linguists use to refer to words borrowed into many different languages. “Taxi” is another good example: most languages in the world call taxis “taxi” or something very similar.)
Read More…
The PanLex Database uses thousands of sources (multilingual dictionaries and databases) to produce word translations. Let’s go under the hood a little on this complex and interesting process. Let’s meet the Platyplex visualization.
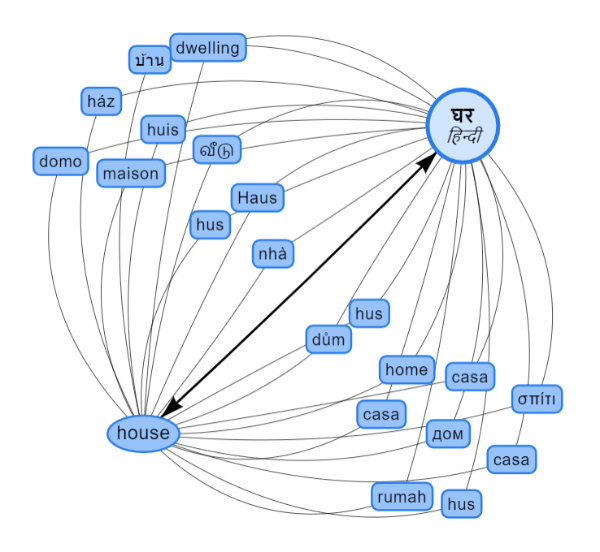
The Platyplex for English house and Hindi घर (ghar).
Read More…
In the first post in this series, we discussed the importance of bringing machine translation to all of the world’s languages and some of the economic and technical challenges in doing so. In this post, we will explore in more detail the current status of technological support for machine translation in under-served languages. Along the way, we will show that PanLex can make an important contribution to several current endeavors.
Existing machine translation platforms and initiatives
Google Translate is probably the most well-known machine translation platform in the world. It currently includes support for 103 languages, including some that are not national languages of any country such as Basque, Cebuano, Hmong, and Kurmanji Kurdish. Translation quality varies widely across languages. It is “good enough” for some purposes in some languages, and it improves regularly. But it has a long way to go, especially in language coverage.
The Apertium project is a free, open-source machine translation platform. Unlike Google Translate, which uses statistical and neural methods, it uses rule-based translation. One advantage of rule-based methods is that once an implementation has been created for one language, it is much less work to adapt it to a closely related language. This has allowed Apertium to develop support for several under-served languages that Google Translate has not, for example Breton (related to Welsh), Northern Sami (related to Finnish), and Tatar (related to Kazakh and Turkish).
Read More…


{kind=link}